Pipeline
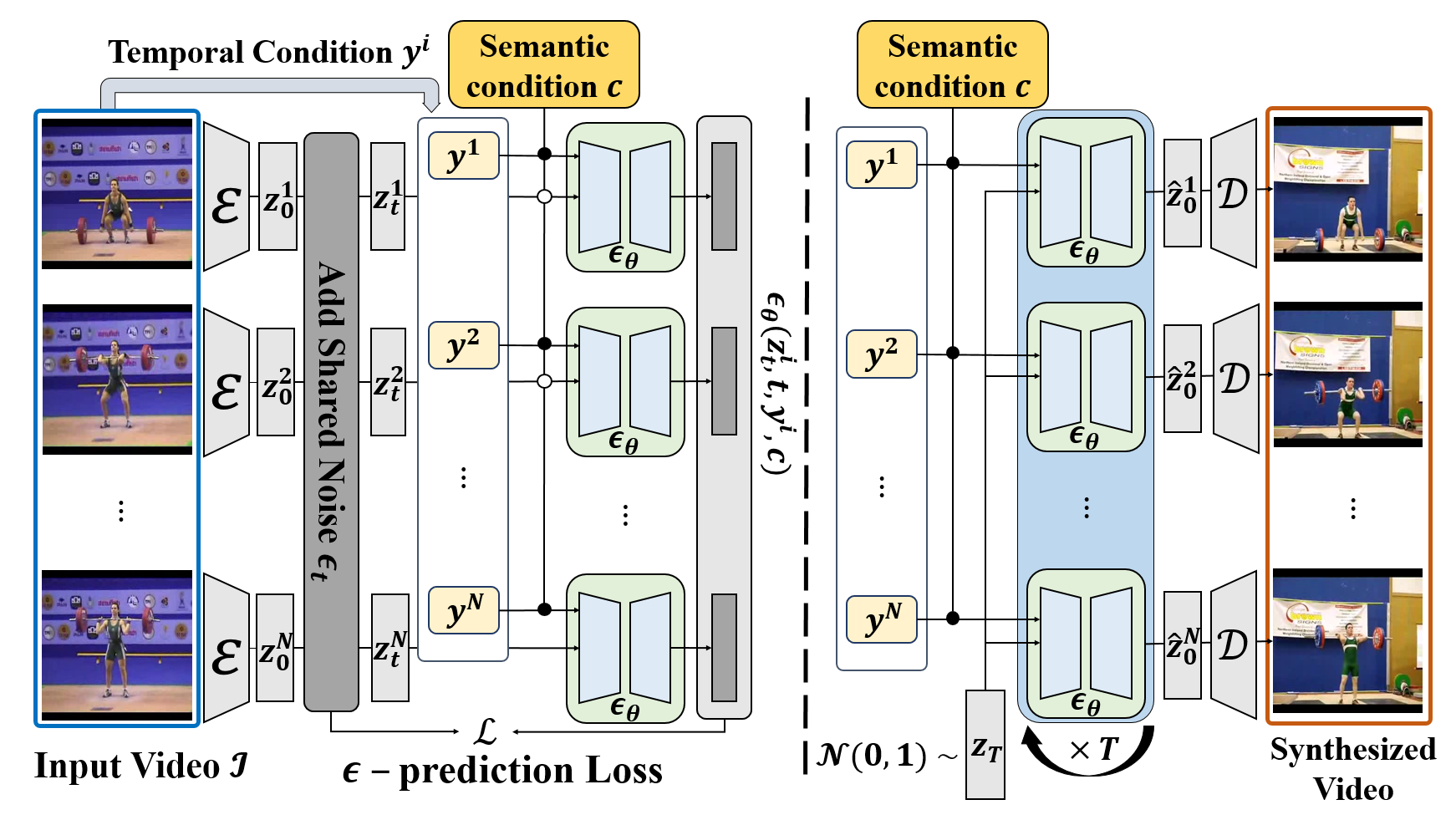
Diffusion models have achieved remarkable success in image generation. However, applying this concept to video generation introduces significant challenges, particularly in maintaining consistency and continuity throughout video frames. Existing approaches primarily address these challenges by incorporating spatiotemporal attention modules or additional temporal conditions. However, they often overlook the impact of non-shared noise between frames in the diffusion process, which can disrupt both semantic coherence and consistent stochastic details in the video. To tackle this problem, we introduce the Sector-Shaped Diffusion Model (S2DM), which employs a sector-shaped diffusion process with shared noise across frames under specific conditions. S2DM ensures that video frames maintain consistent semantic features and stochastic details, while preserving continuous temporal characteristics through guided conditions. We evaluate S2DM on various conditional video generation tasks, using optical flow or posture information as temporal conditions, and descriptive text or reference images as semantic conditions. Experimental results demonstrate that S2DM outperforms existing methods in generating videos with thematic coherence and smooth narrative progression. For text-to-video generation, where temporal conditions are not explicitly provided, we propose a three-step generation strategy that decouples the generation of temporal characteristics from semantic features. Our results can be viewd at https://s2dm.github.io/S2DM/.
Reference
Ours
Disco [Wang et al.]
Magic Animate [Xu et al.]














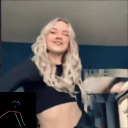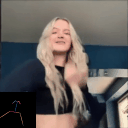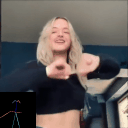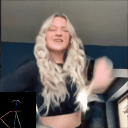



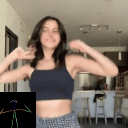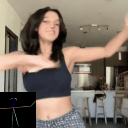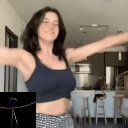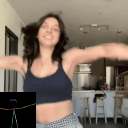



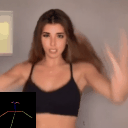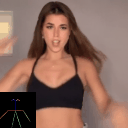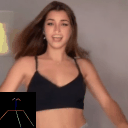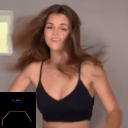

Ours
(Flow Conditioned)
Ours
(Text Conditioned)
LFDM [Ni et al.]
A lady with glasses, wearing a black T-shirt and black jeans is right arm swipe to the right



A lady with glasses, wearing a floral sweater and black jeans is knock on door



A lady with glasses, wearing a red sweater and brown pants is draw circle clockwise



A lady with glasses, wearing a red sweater and brown pants is knock on door



A lady with glasses, wearing a red sweater and brown pants is stand to sit



A man wearing a gray T-shirt and green pants is draw circle counter clockwise



A man wearing a gray T-shirt and green pants is right arm swipe to the left



A man with glasses, wearing a black coat and blue jeans is squat



A man with glasses, wearing a blue shirt and black jeans is draw triangle



Ours
(Flow Conditioned)
Ours
(Text Conditioned)
LFDM [Ni et al.]
Person 010 is making surprise expression



Person 020 is making fear expression



Person 020 is making happiness expression



Person 039 is making fear expression



Person 076 is making happiness expression



Person 065 is making fear expression



Reference Image
Ours
(Flow Conditioned)
SVD [Andreas et al.]





















A lady with glasses, wearing a red sweater and brown pants is knock on door.

A man wearing a gray T-shirt and green pants is right arm swipe to the left

A man with glasses, wearing a blue shirt and black jeans is sit to stand

A lady with glasses, wearing a red sweater and brown pants is stand to sit

A man with glasses, wearing a black coat and blue jeans is right arm throw

A man wearing a gray T-shirt and green pants is draw circle counter clockwise

A man with glasses, wearing a blue shirt and black jeans is draw circle counter clockwise

A lady with glasses, wearing a black T-shirt and black jeans is right arm swipe to the right

Training Shared Noise
Sampling Shared Noise
(Ours)
Training Shared Noise
Sampling Non-shared Noise
Training Non-shared Noise
Sampling Non-shared Noise
Training Non-shared Noise
Sampling Shared Noise
A man with glasses, wearing a black coat and blue jeans is tennis forehand swing




A man with glasses, wearing a blue shirt and black jeans is walking




Person 020 is making happiness expression




Person 076 is making happiness expression




TBA